Your Autonomous AI Search Analyst
Lantern's Monitor Agent runs after every AI visibility scan, finds citation gaps, and acts on them automatically. Here's exactly how it works.

On this page
On this page
Every marketing team has the same problem.
AI search is moving fast. ChatGPT updates its behavior. Perplexity starts citing a new source in your category. A competitor publishes something that earns citations on three queries you were winning last week. Your brand drops out of an AI answer it has been appearing in for two months.
None of this shows up in your Google Analytics. None of it triggers a ranking alert. None of it appears in your Monday morning report.
It happens silently. And by the time your team notices , if they notice at all, the gap has been open for weeks.
This is the problem Lantern's Monitor Agent is built to solve.
What the Monitor Agent Is
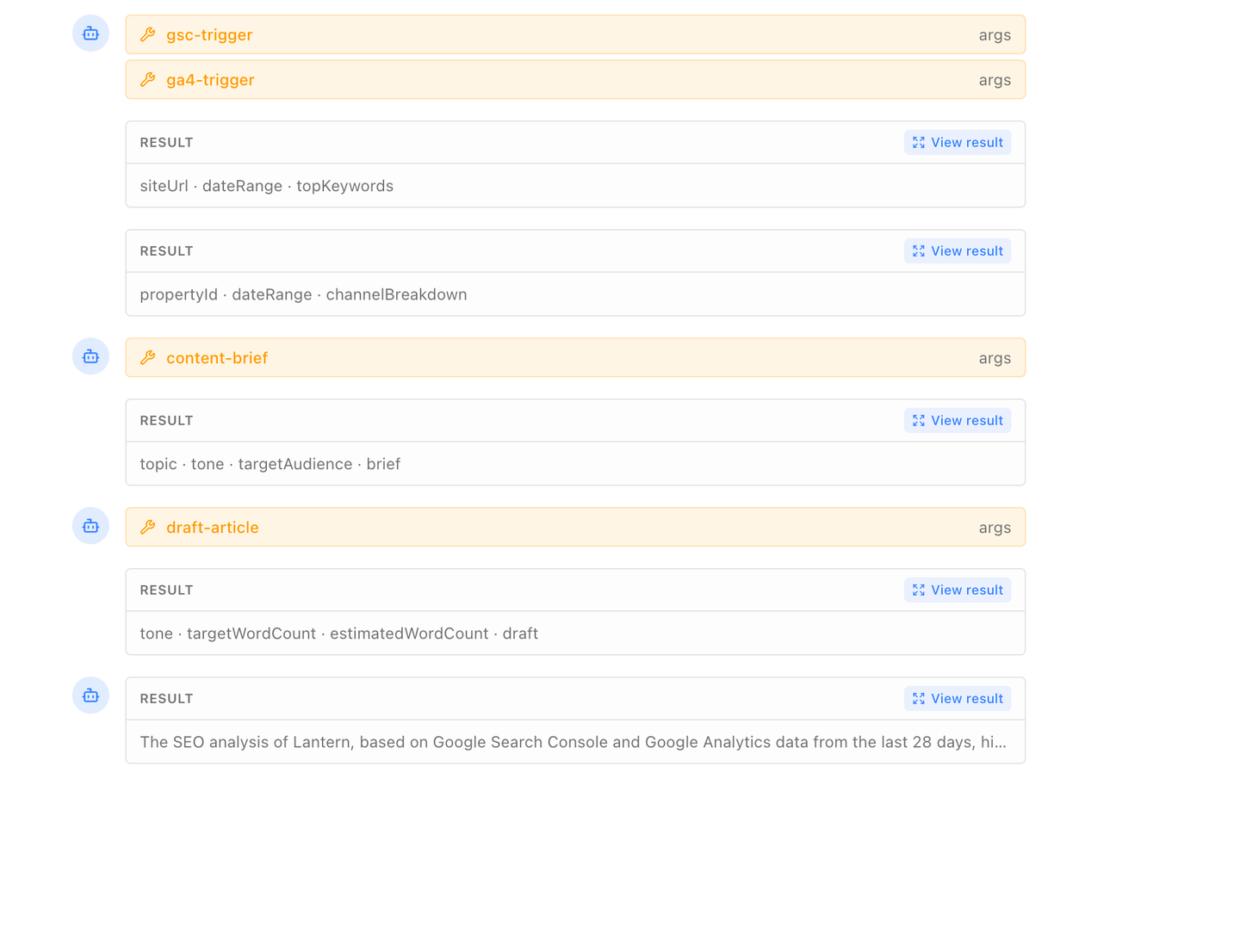
The Monitor Agent is an autonomous AI agent that runs continuously in the background of your Lantern account. Every time Lantern completes an AI visibility tracking run, scanning ChatGPT, Perplexity, Gemini, and Claude for your brand across every tracked prompt the Monitor Agent wakes up, reads the results, evaluates what changed, and independently decides what to do next.
It is not a report. It is not an alert. It is not a scheduled email digest.
It is an agent that reasons about your AI search position, identifies what is most important to act on, and acts.
Every Brand Kit in Lantern can have one designated Monitor Agent. Once set, it runs after every visibility scan without being asked. It does not require a workflow to be triggered manually. It does not wait for a human to review the data and decide what matters. It reads the scan, forms a judgment, and executes.
What It Actually Does After Every Scan
When the Monitor Agent receives the results of a visibility scan, it is given three things: your current Visibility Score, the previous Visibility Score, and a summary of what changed between the two.
From that input, the agent independently determines the appropriate response. Depending on what the data shows, that response might be any of the following:
Researching a citation gap. If your brand dropped off a query it was previously appearing on, or if a competitor gained a citation on a query where you are absent, the Monitor Agent can initiate a research workflow pulling Google Search Console data, running a Perplexity search on the topic, analyzing competitor content, and building a content brief targeted at winning that query back.
Drafting content. If the gap analysis points to a missing piece of content a query your buyers are asking that you have no answer for the Monitor Agent can trigger the full content creation workflow: research, brief, draft, optimization, and publication to your connected CMS. A gap identified on Tuesday evening can be a published article by Wednesday morning.
Notifying your team. If the change is significant a sharp drop in Visibility Score, a competitor gaining ground on a high-priority query, a new external source appearing that is affecting your citations the Monitor Agent sends a summary to your connected Slack channel. Your team wakes up to a clear, specific briefing on what changed and what is being done about it.
Updating your knowledge base. If new content has been published by your team or by competitors that is relevant to your brand's citation strategy, the Monitor Agent can add it to your knowledge base, ensuring that every future content workflow has access to the most current information.
The Monitor Agent does not execute all of these on every run. It evaluates the data and determines which response is appropriate given the magnitude and nature of the change. A minor fluctuation in Visibility Score requires a different response than a sudden drop across multiple high-priority prompts. The agent makes that judgment call without being asked.
The Problem With Manual Monitoring
To understand why the Monitor Agent is significant, it helps to understand what monitoring AI search looks like without it.
A marketing team tracking AI search manually opens ChatGPT, Perplexity, Gemini, and Claude. They run a set of queries the questions their buyers are asking, the competitor comparisons relevant to their category, the use case queries they want to win. They document the results. They note where their brand appeared and where it did not. They compare against last week's results. They identify gaps. They decide what to do about them.
This process, done properly across four AI engines and a meaningful number of prompts, takes several hours. It needs to happen at least weekly to be useful because AI engine behavior changes frequently enough that monthly monitoring misses meaningful shifts. In practice, most teams do it inconsistently, at lower frequency than required, and with less prompt coverage than their competitive landscape demands.
The structural problem is not effort. It is frequency and coverage. AI search does not move on a weekly cadence. A competitor can publish a piece of content that starts earning citations within 48 hours. A model update can change citation patterns overnight. A new review on G2 can shift how an AI engine represents your brand before your next scheduled monitoring session.
The Monitor Agent closes that gap by running after every visibility scan, at whatever frequency your plan supports weekly on Starter, daily on Pro and Enterprise. It does not have off days. It does not have competing priorities. It does not need to be reminded. It runs, it evaluates, and it acts.
The Visibility Score It Monitors
The Monitor Agent's primary input is Lantern's Visibility Score a single metric that represents how present your brand is in AI-generated answers across the engines you are tracking.
The score is calculated from the visibility tracking runs that Lantern conducts against your prompt library. For each prompt, Lantern records whether your brand appeared, where in the response it appeared, what sentiment the mention carried, and what sources the AI engine cited. The Visibility Score aggregates these data points into a normalized metric that can be tracked over time and benchmarked against competitors.
When the Monitor Agent receives a new Visibility Score, it is not just looking at the number. It is looking at the delta what changed, on which prompts, on which engines, and in which direction. A Visibility Score that dropped by 8 points because a competitor gained citations on three high-priority queries is a different situation from a score that dropped because one low-priority prompt stopped returning results. The Monitor Agent evaluates the composition of the change, not just the magnitude.
This is what makes the Monitor Agent meaningfully different from a simple alert system. An alert fires when a number crosses a threshold. An agent evaluates why the number moved, determines what the most important response is, and takes that response.
The Monitor Agent and Your Team
A question that comes up when marketing teams encounter the Monitor Agent for the first time is a reasonable one: if the agent is making decisions and taking actions autonomously, where does the human team fit?
The answer is in the approval layer.
Lantern's agent workflows include an optional Wait for Approval step. When enabled, the Monitor Agent pauses before publishing any content it has drafted and sends the draft to a designated reviewer in Slack, by email, or within the Lantern dashboard. The content goes live only after a human approves it.
This means the Monitor Agent is not operating without oversight. It is handling the execution work the monitoring, the gap identification, the research, the drafting while the human team handles the judgment calls that require strategic context the agent does not have. Is this the right time to publish a comparison page against this competitor? Does this draft reflect our current positioning? Is there a reason we should not be targeting this query right now?
Those decisions belong to the team. Everything upstream of them belongs to the Monitor Agent.
The teams that get the most value from the Monitor Agent are not ones that have removed human judgment from the process. They are ones that have removed human labor from the execution process and returned their team's attention to the decisions that actually require a human.
Setting Up the Monitor Agent
Setting a Monitor Agent for a Brand Kit takes less than five minutes.
Within your Brand Kit settings, you designate which agent should serve as the Monitor Agent for that brand. That agent will receive the results of every visibility scan as its trigger input. You configure what actions it is authorized to take autonomously and which actions require approval before execution. You connect the integrations it needs your CMS for content publishing, Slack for notifications, Google Search Console for keyword gap data.
Once configured, the Monitor Agent runs after every scan without further setup. You can review its run history, see exactly what it identified and what actions it took, and adjust its configuration at any time.
One Monitor Agent per Brand Kit. For agencies or teams managing multiple brands, each brand has its own Monitor Agent running independently — so a shift in AI search position for one client does not compete with the monitoring workload for another.
What the Monitor Agent Is Not
It is worth being precise about the boundaries of what the Monitor Agent does.
It is not a replacement for strategic marketing judgment. It does not set your brand positioning, determine which markets to prioritize, or make decisions that require understanding of your competitive strategy, customer relationships, or business context. Those decisions require human judgment and always will.
The Monitor Agent identifies gaps and executes the workflows most likely to close them based on Lantern's citation data. Whether a specific piece of content earns citations depends on factors beyond execution quality including domain authority, competitive density, and AI engine behavior that can change with model updates. The Monitor Agent maximizes the consistency and speed of your response to AI search changes. It does not guarantee the outcome of those responses.
It is not a set-and-forget system that requires no attention. The Monitor Agent runs autonomously, but it runs best when your Brand Kit is current when your competitor list reflects the actual competitive landscape, when your prompt library covers the queries your buyers are asking, and when your knowledge base contains your most recent content. Teams that invest fifteen minutes per month keeping their Brand Kit current get significantly better Monitor Agent performance than teams that configure it once and never revisit it.
Key Takeaways
- The Monitor Agent is an autonomous AI agent that runs after every Lantern visibility scan, evaluates what changed in your AI search position, and independently decides what to do about it
- It can research citation gaps, trigger content creation workflows, notify your Slack channel, and update your knowledge base based on its evaluation of what the data requires
- Every Brand Kit can have one designated Monitor Agent for agencies managing multiple brands, each brand runs its own independent Monitor Agent
- The Monitor Agent is not a reporting tool or an alert system it is an agent that reasons about your AI search position and acts on what it finds
- Human oversight is preserved through the Wait for Approval step, which pauses content publication until a team member reviews and approves the draft
- Setup takes under five minutes connect your Brand Kit, designate the agent, configure approval settings, and it runs automatically from the next visibility scan forward
- The Monitor Agent handles execution; your team handles strategy the combination produces AI search output equivalent to a team several times larger operating manually